AI가 기똥차게 말아주는 그림일기 서비스, "오늘 하루를 그려줘" 앱에서 백엔드 개발을 맡고 있다.
https://github.com/tipi-tapi/ai-paint-today-BE
GitHub - tipi-tapi/ai-paint-today-BE: 🖼️ AI가 말아주는 오늘 하루의 그림 일기, "오늘 하루를 그려줘"
🖼️ AI가 말아주는 오늘 하루의 그림 일기, "오늘 하루를 그려줘" 🖼️. Contribute to tipi-tapi/ai-paint-today-BE development by creating an account on GitHub.
github.com
ios, 안드로이드 모두 출시를 완료했고, 현재는 유지보수와 홍보에 힘쓰고 있다.
동아리 프로그라피에서 1등을 한 서비스인 만큼, 모두 한번씩 사용해보면 좋겠다 :)
캐시를 도입한 이유
우리 서버가 제공하는 다양한 API 중 감정 목록 조회 API는 반복적으로 같은 데이터를 반환한다.
새로운 감정이 추가되거나, 기존의 감정이 비활성화/삭제되지 않는한, 같은 데이터를 반환한다.
그래서 그때마다 DB에서 조회해오는건 불필요하므로, 캐시를 도입했다.
특별히 redis와 같은 외부 메모리의 캐시를 이용하는 것 보다는, 간단한 데이터 이므로 굳이 복잡성을 올릴 것 없이 로컬 인메모리에서 캐싱처리하도록 했다.
이때 CaffeineCache를 사용했다.
분산된 환경에서 공통의 캐싱을 적용하지 않아도 되고, 가벼운 경량 저장소만으로 충분하다고 생각했기 때문에 해당 기술을 도입했다.
jmeter로 테스트하기
그래서 캐시를 도입해서 얼마나 개선이 된 것인지를 측정해볼 필요가 있다.
jmeter를 사용해서 테스트했고, https://jmeter.apache.org/download_jmeter.cgi 에서 다운받아서 실행하면 된다.
Binaries 섹션에서 zip 파일 다운 받아서, /bin/jmeter.sh를 실행하면 프로그램을 사용할 수 있다.
실행 계획(시나리오) 세우기
여러가지 실행계획을 세웠다.
- 100개의 순간적인 동시 요청
- 200개의 순간적인 동시 요청
- 500개의 순간적인 동시 요청
- 사용자를 초당 10명씩 늘려서 100명까지 늘리고, 총 5분간 요청
- 사용자를 초당 5명씩 늘려서 300명까지 늘리고, 총 3분간 요청
- 100개의 동시 요청을 1분간 테스트
그래서 이 5개의 테스트를 모두 수행해봤는데, 사실 300명이나 500명 같은 수준으로 우리 서비스를 이용할 것이라고 생각하지 않았기에 "100개의 동시 요청을 1분간 테스트"하는 계획으로 최종적인 결론을 냈다.
100개의 동시 요청을 1분간 테스트 - 캐시 X
캐시를 도입하지 않은 환경에서, 100개의 동시 요청을 1분간 테스트하였다.
스레드 그룹 설정
- 스레드 수 : 100
- ramp-up : 0
- 루프카운트 : X
- 스레드 생명주기 지정 : 60초
총합 보고서

- 표본 수 ( 총 요청 수 ) : 14148
- 평균 응답 시간 : 419 ms
- 처리량 : 235.7 tps
- 오류 : 0 %
Response Times Over Time
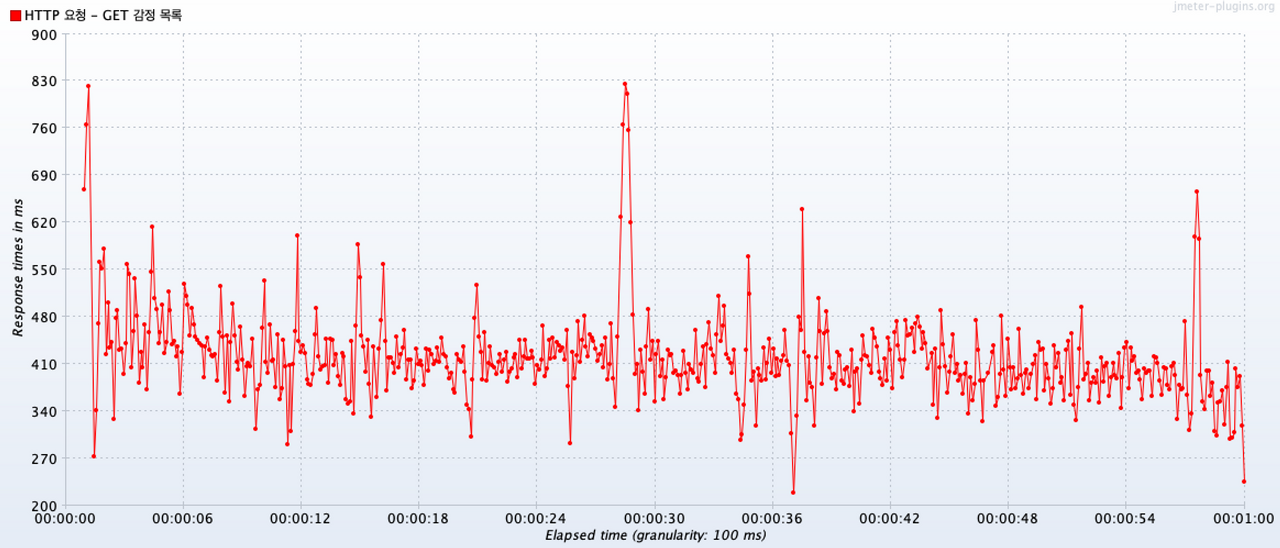
시간에 따른 응답속도는 300~600 정도의 범위에서 이루어졌다.
Transactions per Second
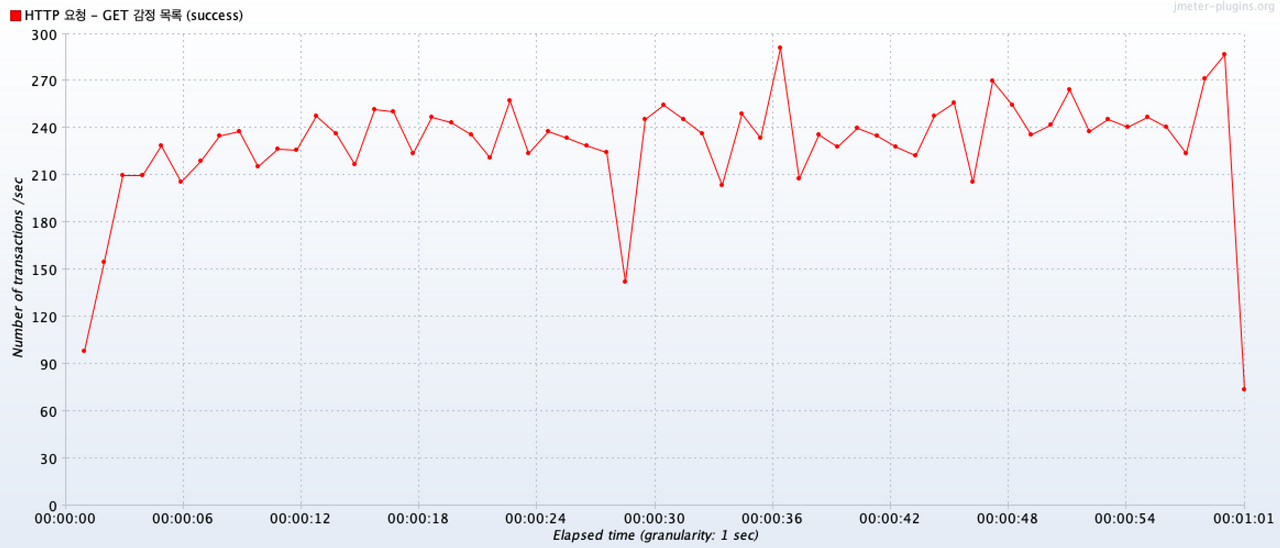
시간에 따른 트랜잭션은 200 ~ 270 정도의 범위에서 이루어졌다.
테스트 결과 리뷰
평균적인 응답시간이 1초 내에서 이루어져 나쁜 결과를 보여주지는 않았다.
그래서 수치적으로 나쁘진 않지만, 반복적으로 요청되는 값이므로 잘 활용하기 위해서 캐시를 도입했다.
캐시를 도입하지않아도 빠르긴 했지만, 얼마나 개선되는지 확인해보자.
100개의 동시 요청을 1분간 테스트 - 캐시 O
캐시를 도입한 환경에서, 100개의 동시 요청을 1분간 테스트하였다.
스레드 그룹 설정
- 스레드 수 : 100
- ramp-up : 0
- 루프카운트 : X
- 스레드 생명주기 지정 : 60초
총합 보고서

- 표본 수 ( 총 요청 수 ) : 32725
- 평균 응답 시간 : 179 ms
- 처리량 : 544.4 tps
- 오류 : 0 %
평균 응답 시간, 처리량 모두 우수하다.
최대값또한 1초를 넘기지 않았다.
Response Times Over Time

시간에 따른 평균 응답 시간 분포를 보면, 대부분 140 ~ 280 정도의 범위 내에서 수행되었다.
Transactions per Second
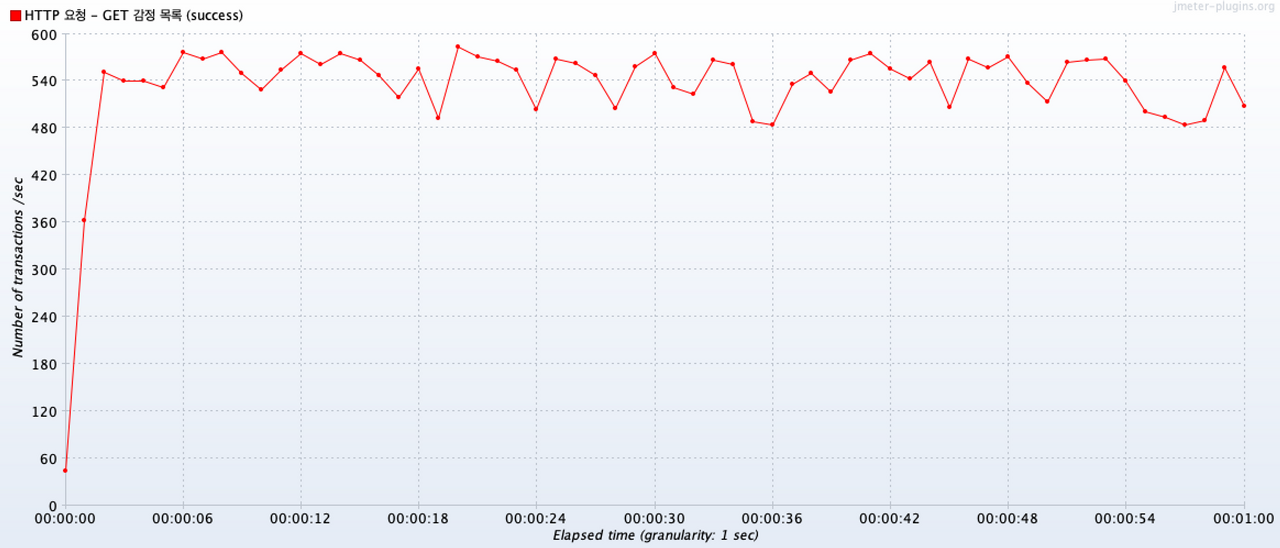
시간에 따른 처리량 분포를 보면, 480 ~ 600 내의 범위에서 수행되었다.
테스트 결과 리뷰
처리량과 응답 시간 모두 우수하다.
평균 응답 시간 분포나, 처리량 분포에서도 캐시를 적용했을때 범위가 더 좁혀졌다.
평균 응답속도는 2.34배 줄어들었고(419 ms →179 ms), 처리량은 2.3배 늘어났다. ( 235.7 tps → 544.4 tps )
성능 테스트 결론
100명이 동시에 1분 동안 요청하는 상황에서, 캐시를 도입하지 않았을 때는 응답시간이 평균적으로 1초를 넘지 않았지만, 1초를 초과하는 요청들도 있었다.
같은 상황에서, 캐시를 도입했을 때에는 평균 응답 시간은 두배 감소하고, 처리량은 두배 증가했고, 최대 응답 시간도 832초로 1초 미만이었다.
따라서, 캐시를 도입함으로써 응답 시간과 처리량 측면에서 2배 정도씩 개선되었고, 100명이 1분간 지속적으로 동시에 요청해도 안정적으로 핸들링이 가능함을 알 수 있다.
결론에 포함시키지 않았던, 시행착오 성능테스트
위에서 다른 시나리오의 테스트로 결론은 지었지만, 내가 수행했던 다른 테스트도 공유해볼까 한다.
[ 캐시 O ] 100개, 200개, 500개의 동시 요청에 따른 총합 보고서 데이터
100개의 동시 요청
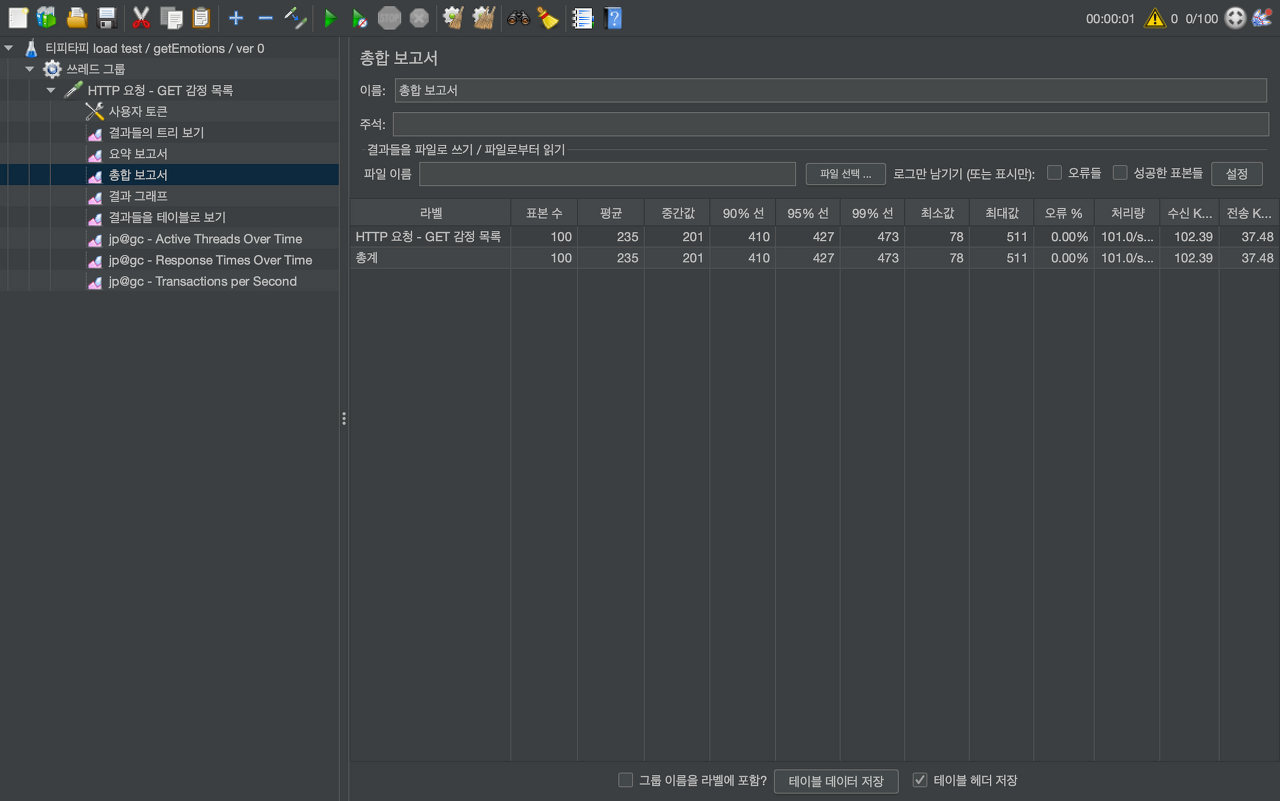
- 평균 235ms
- 최소 78ms
- 최대 511ms
- 오류 없었음
- 처리량 Throughput ( tps 단위. Transaction per second ) 101.0 tps
- 초당 약 101개의 요청을 처리할 수 있다.
200개의 동시 요청
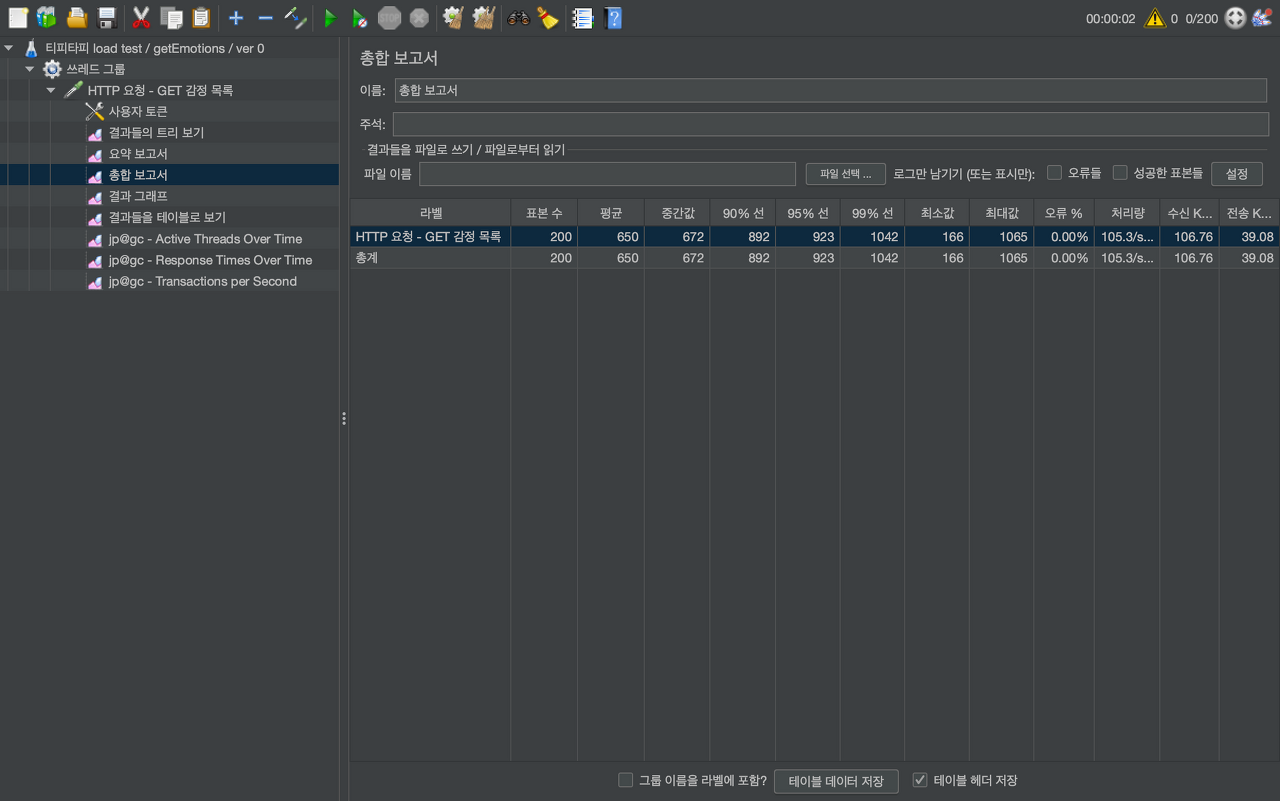
- 평균 650ms
- 최소 166ms
- 최대 1065ms
- 오류 없었음
- 처리량 105.3 tps
500개의 동시 요청
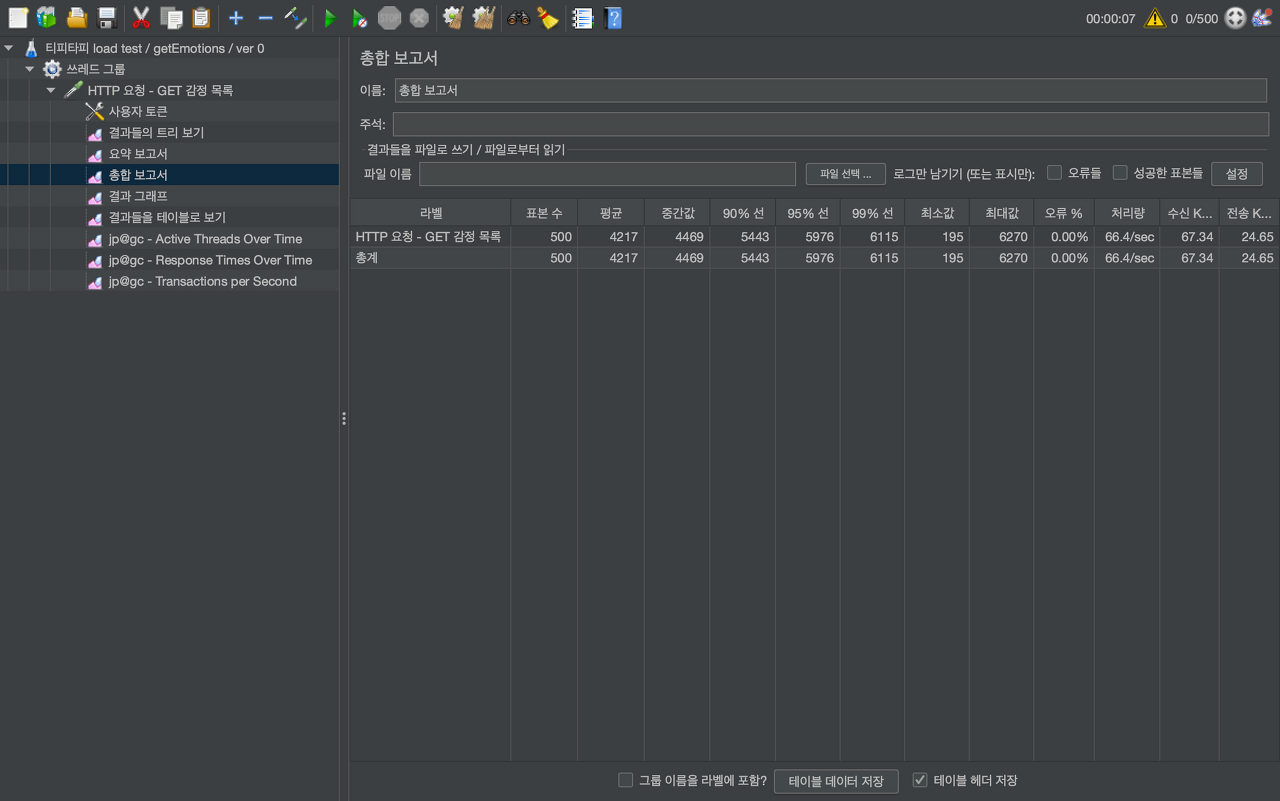
- 평균 4217ms
- 최소 195ms
- 최대 6270ms
- 오류 없었음
- 처리량 68.4 tps
이 테스트들로 내린 결론은 아래와 같다.
- 500개에서는 평균 응답속도가 4초대를 기록했으므로 안정적으로 처리한다고 할 수 없다.
- 이렇게 동시 요청 단위를 직접 늘려가며 각각 테스트하는 것보다는, 시간이 흐를수록 동시 요청 스레드 수를 늘려 한계점을 찾는 것이 좋겠다.
따라서 사용자를 점차 늘려 한계점을 찾는 테스트를 수행했다.
[ 캐시 O ] 사용자를 초당 10명씩 늘려서 100명까지 늘리고, 총 5분간 요청
Active Threads Over Time
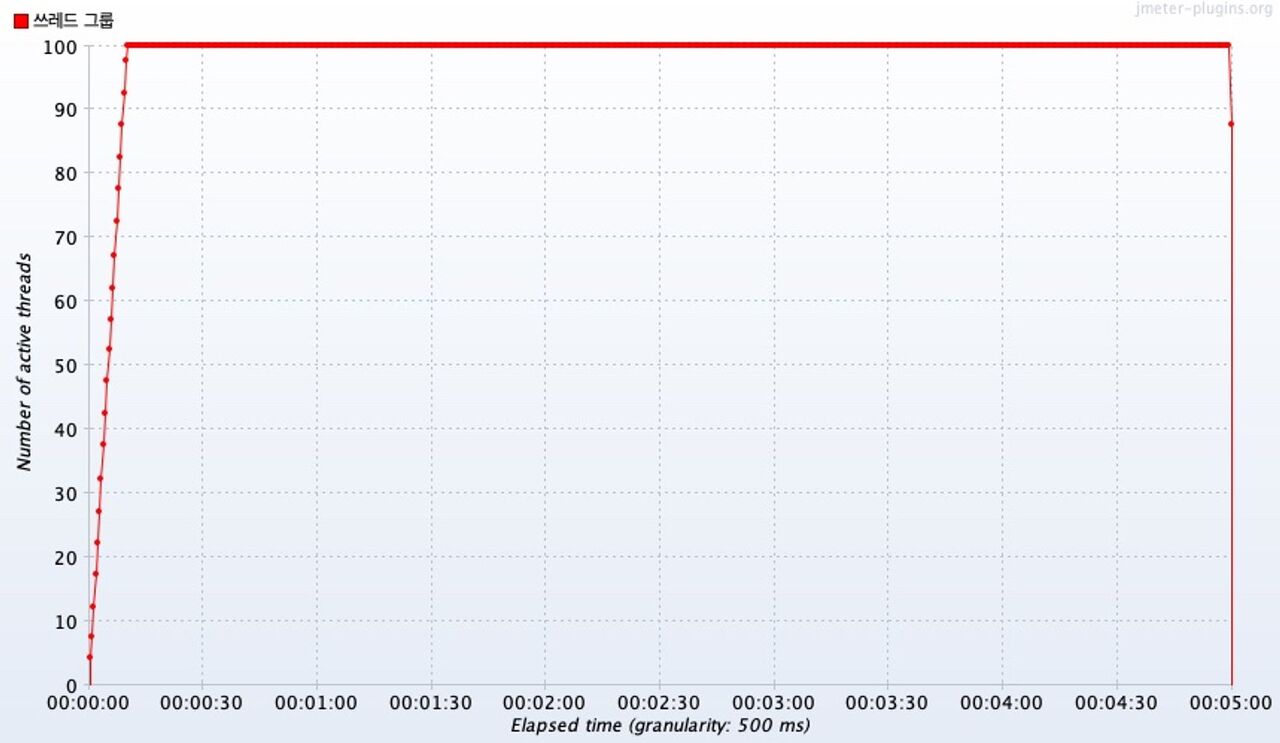
Thread Group 설정에 맞게 10초에 100개의 스레드 요청에 도달했다. 이후 남은 4분 50초 동안 100명의 스레드 요청을 유지했다.
시간에 따른 처리량 변화 그래프 Transactions per Second
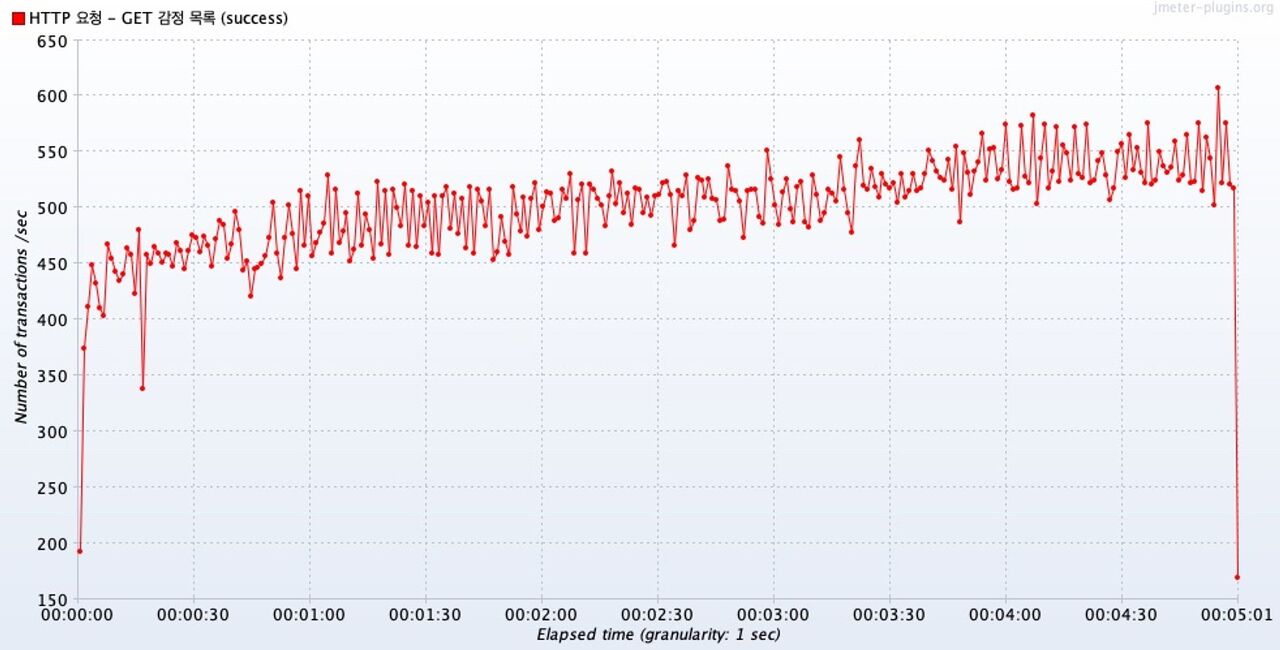
동시 요청 Thread의 수가 점차 증가한 10초까지는 그래프가 급격하게 변했다. ( 이 부분은 너무 급격하게 요청량을 높인것 같아서 이후 테스트에서 개선할 것이다. )
10초 이후부터는 100개의 스레드를 유지하는데, 이때 시간이 흐름에 따라서 처리량이 완만하게 증가했다.
따라서 특별한 Saturation Point가 보이지 않는다.
시간에 따른 응답 시간 Response Times Over Time
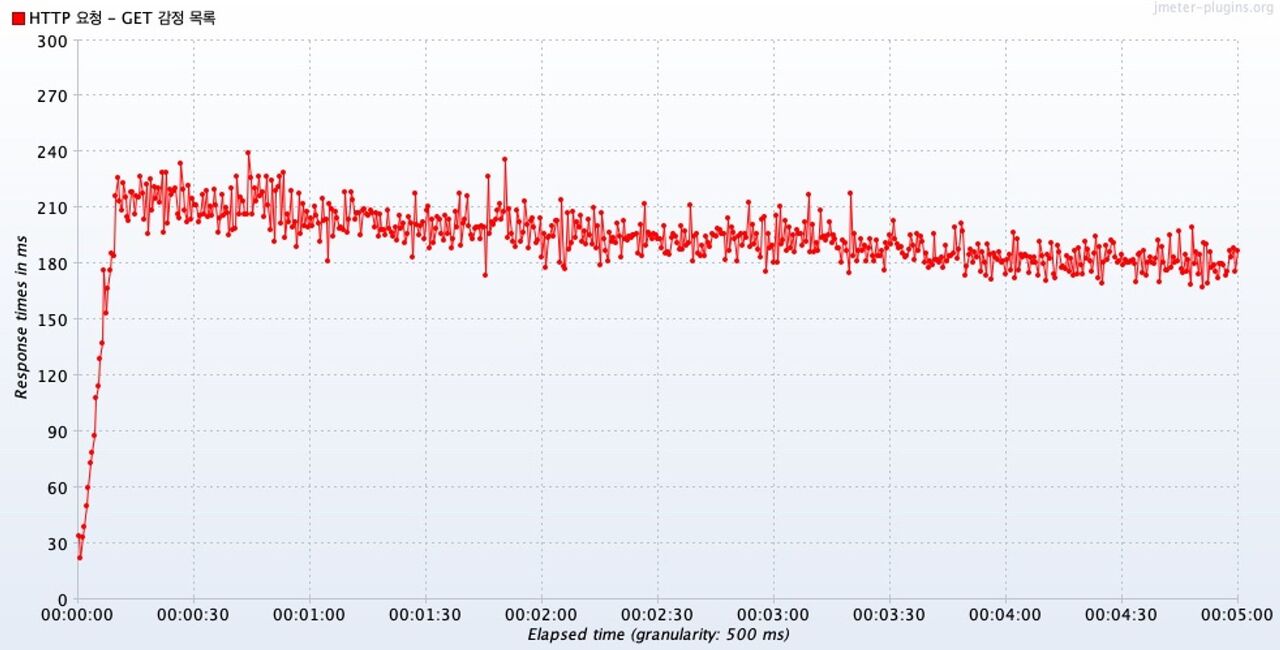
100명의 동시 요청을 처리하는 10초 ~ 5분 동안 응답 시간이 갑자기 느려진 지점은 없고, 오히려 완만하게 줄어드는 추세이나 큰 관점으로는 거의 동일한 응답시간을 보였다.
총합 보고서
모든 데이터를 총합해서 보면, 평균적으로 192ms가 소요되었고, 최소 8ms 최대 844 ms가 소요되었다. 오류는 없었다.
테스트 결과
10초 안에 100개의 동시 요청 수를 도달하다보니, 세부적인 수치가 눈에 띄지 않았다.
또한, 100개는 안정적으로 핸들링이 가능해 보이므로, 더 많은 양의 동시 요청 수를 검증하고, 그럼으로써 동시 요청 스레드 수의 한계를 찾자.
[ 캐시 O ] 사용자를 초당 5명씩 늘려서 300명까지 늘리고, 총 3분간 요청
스레드 그룹 설정
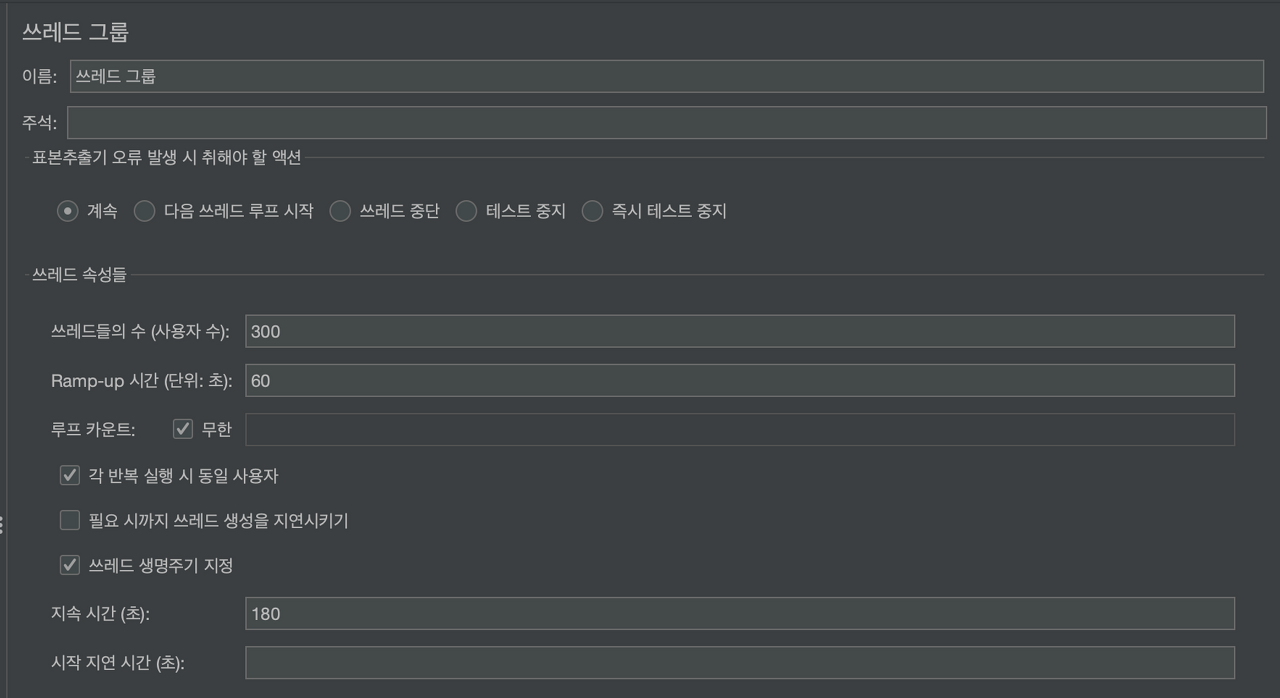
쓰레드 그룹을 위와 같이 설정하였다.
1분이 되었을 때, 동시 요청 수가 300명에 도달한다.
나머지 2분 동안 동시 요청 300개로 요청한다.
Active Threads Over Time
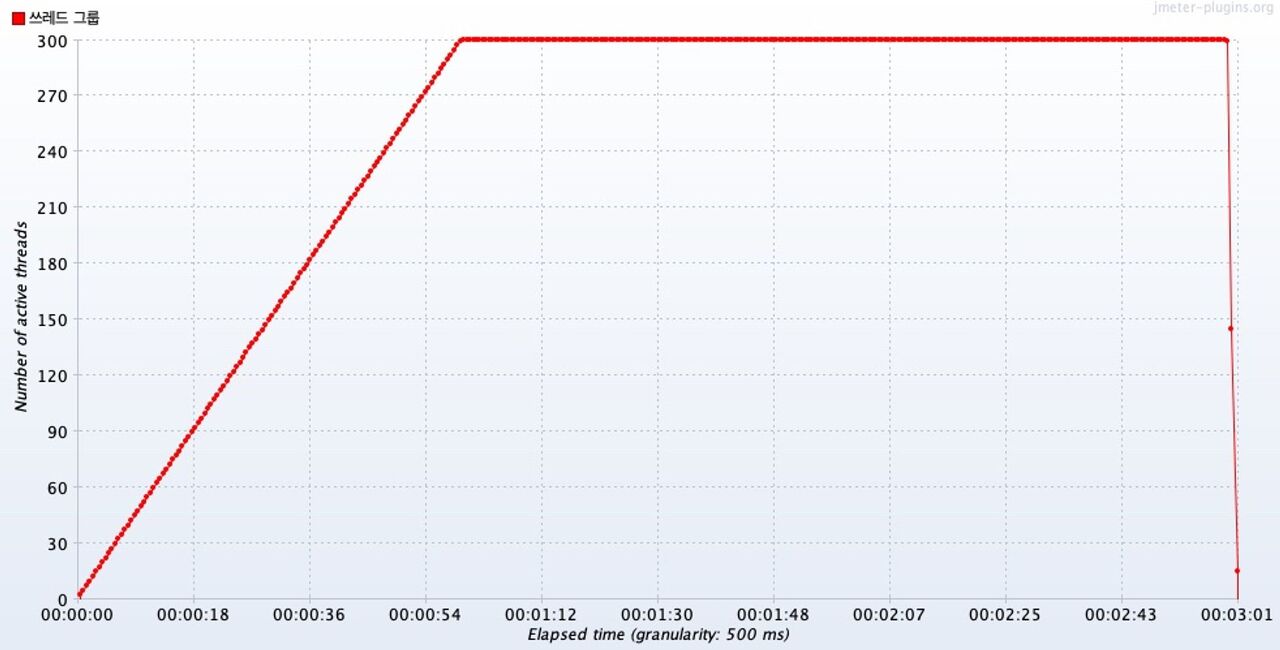
1분이 되었을때 동시 요청 스레드의 수가 300에 도달했고, 남은 2분 동안 300개의 스레드가 동시 요청을 보냈다.
Transactions per Second
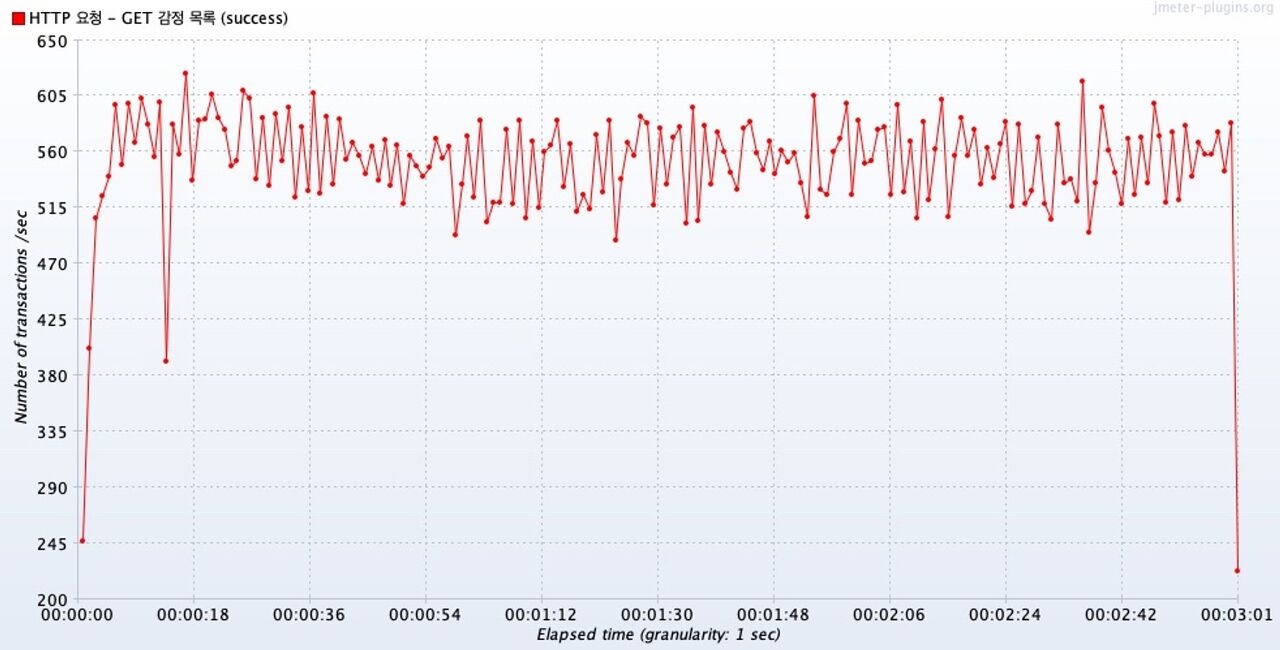

2초뒤부터, 즉 15개의 동시 요청부터 처리량은 500tps ~ 600tps 범위를 유지했다.
(13초 쯤 예외는 일시적인 오류로 보인다.)
최대 300개의 동시 요청 범위 내에서 처리량은 안정적인 범위를 유지했다.
다시한번 동일한 조건으로 시간당 트랜잭션양을 확인했는데 역시나 동일하게 500tps ~ 600tps 범위를 유지했다.
(Average) Response Times Over Time
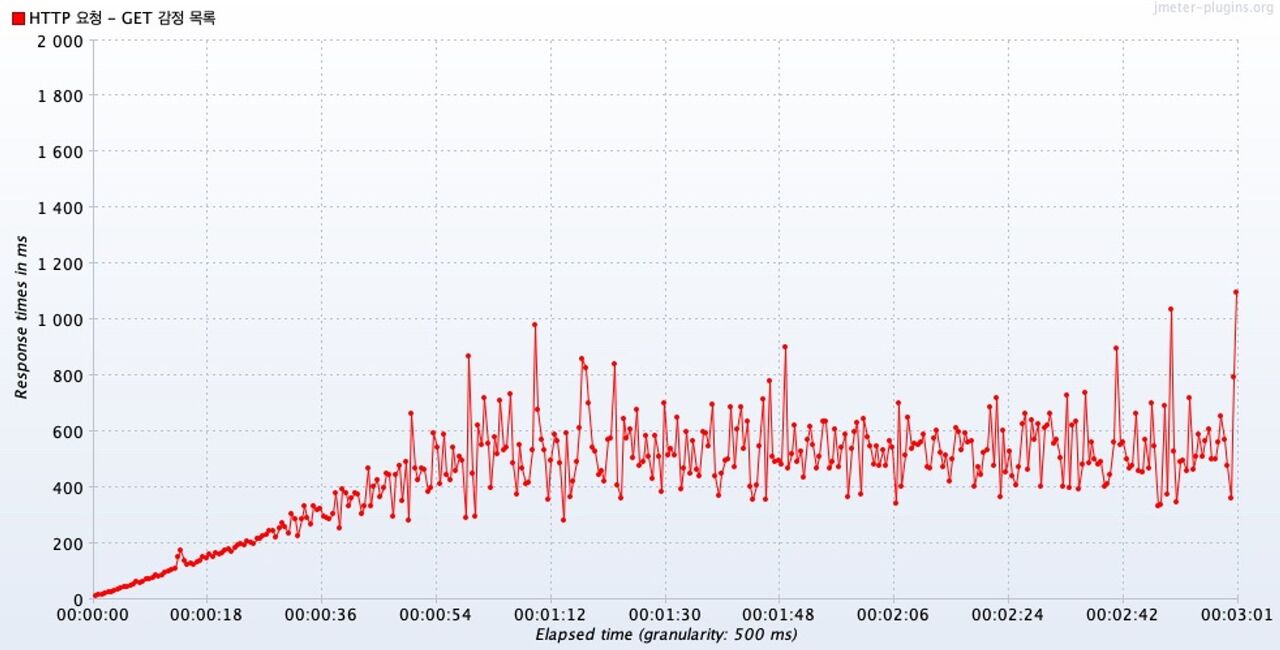


평균 응답시간은 꽤 범위가 큰편이나, 1초 내로 처리된다.
첫번째 그래프는 3분 동안의 시간별 응답 시간을 나타내는 그래프,
두번째 그래프는 동시 요청 300개에 도달할때까지인 처음 1분 동안의 시간별 응답 시간을 나타내는 그래프,
세번째 그래프는 동시 요청 300개로 남은 2분간의 시간별 응답 시간을 나타내는 그래프다.
두번째 그래프를 보면, 300개의 동시 요청에 도달할때까지 1차 함수의 형태로 꾸준히 증가하고, 자세히 보면 150개의 동시요청을 초과한다음부터 조금씩 범위가 커진다.
그리고 300개를 동시 요청할 때는 같은 개수의 동시 요청 스레드임에도 범위가 꽤나 크다. 최소 279ms, 최대 1039ms 정도를 기록하였다. 평균적으로는 539ms 정도다.
참고로, 위 그래프에서는 가독성이 떨어져 보기 어렵지만, 동시에 100개의 스레드가 요청했을 때는 응답시간이 164ms 였다.
어쨌든 범위가 꽤 크지만, 캐시 덕분에 평균 응답 속도가 1초를 초과하는 사례는 적었다.
하지만 평균일 뿐, 모든 요청이 이런 범위에 속하진 않았다.
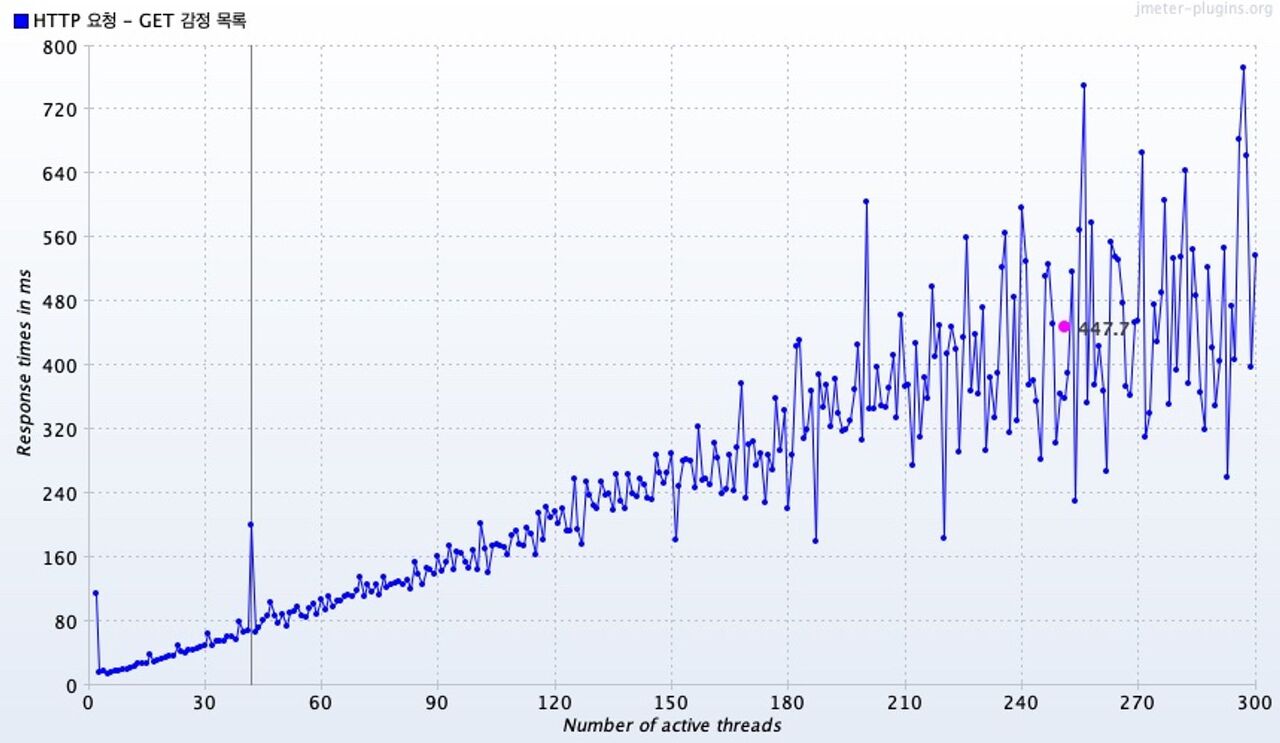
Response Times vs Threads
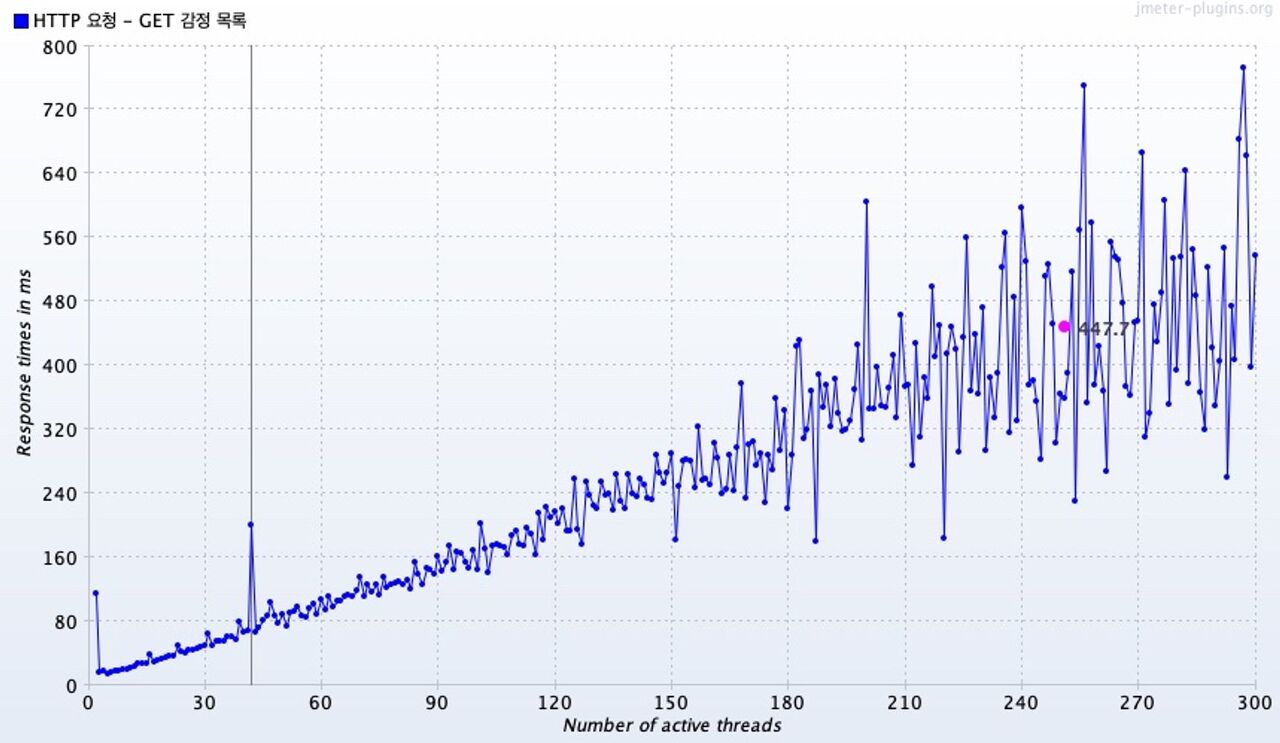
그래프의 핑크색 지점은 총 평균 응답시간을 나타낸다.
동시 요청 수가 증가함에 따라서 응답 시간도 증가하는 추세를 나타냈는데, 200개의 동시 요청을 보냈을 때 부터는 범위가 매우 커졌다.
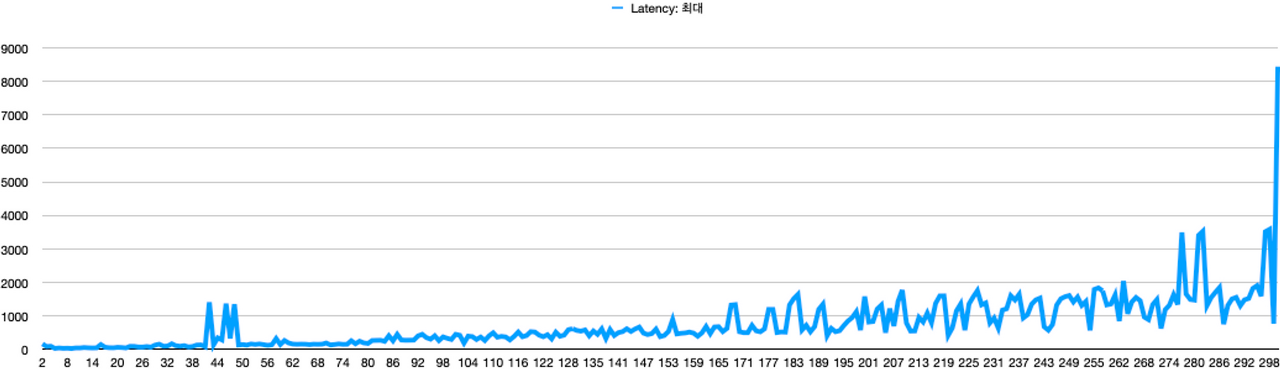
동일한 결과 데이터를 바탕으로, 요청 스레드 수별 최대 응답 시간 그래프로 그렸다.
위 그래프를 통해 동시 요청 스레드 수별 최대 응답 시간을 확인해보면, 168개의 동시 요청부터 최대 1초를 초과했다.
물론, 168개 이상의 동시 요청 모두가 최대 응답 시간이 1초를 초과한 것은 아니다.
263개의 동시 요청부터 최대 2초를 초과했다.
이 그래프를 통해서 알 수 있는 점은 168개의 동시 요청 이전에는 모든 요청이 아무리 늦게와도 1초를 초과하지 않았다는 점이다.
Transaction Throughput vs Threads
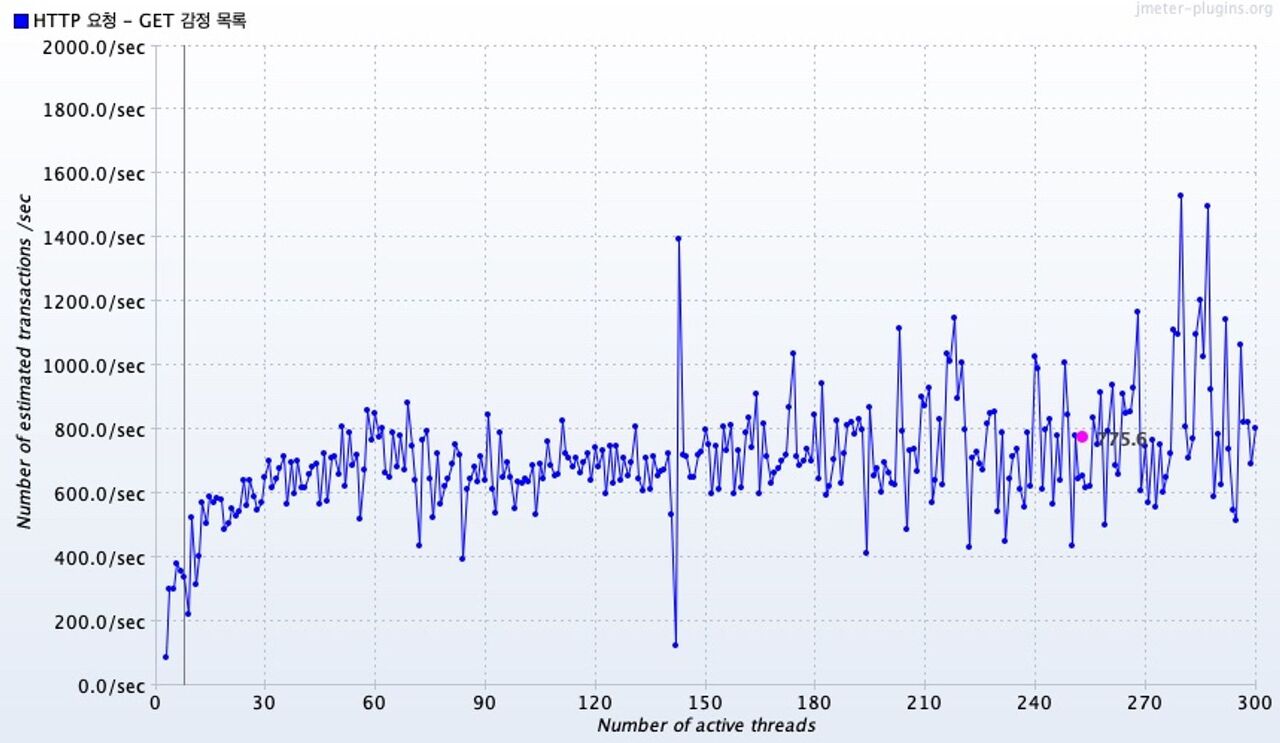
그래프의 핑크색 지점은 총 평균 처리량을 나타낸다.
30개의 동시 요청 부터는 600~800 tps 구간내로 처리량 값을 가지는 데이터가 많았다.
( 더 많이 동시 요청을 해봐야 할것 같지만, ) 특별한 saturation point가 발견되지 않았다.
총합 보고서

모든 데이터를 총합해서 보면, 평균적으로 447ms가 소요되었고, 최소 6ms 최대 8437 ms가 소요되었다. 오류는 없었다.
처리량은 554.8 tps로 나타났다.
이제 캐시를 도입하지 않았을 때에 대해, 성능테스트를 수행해보자.
[ 캐시 X ] 사용자를 초당 5명씩 늘려서 300명까지 늘리고, 총 3분간 요청
Active Threads Over Time
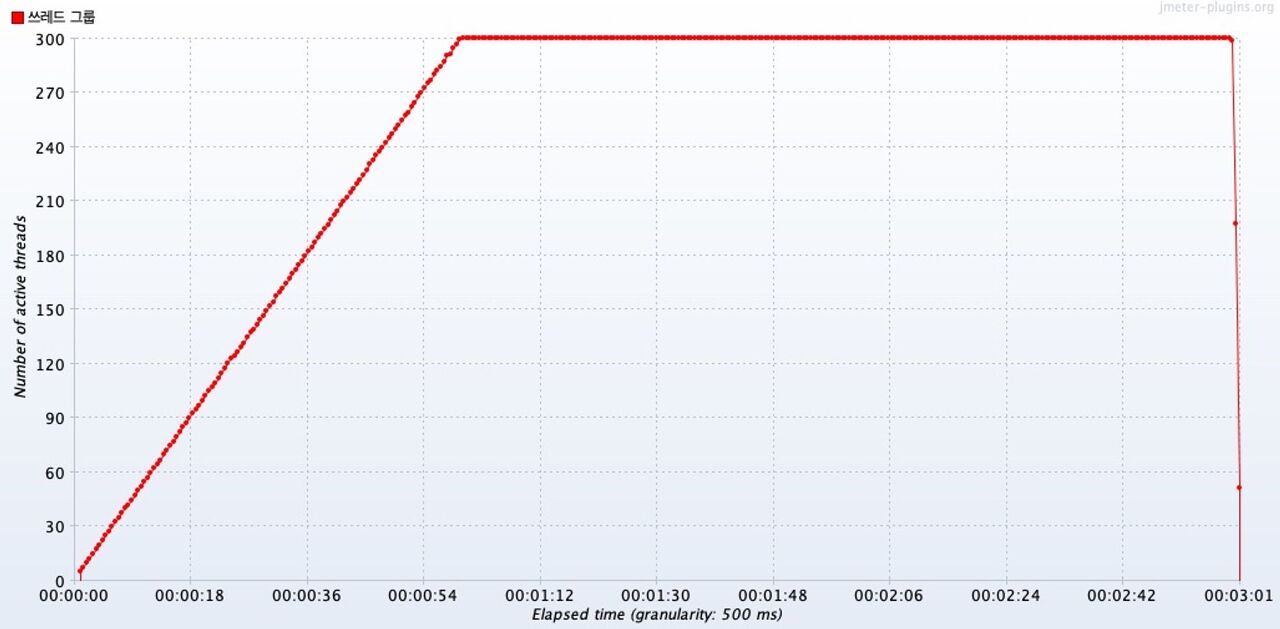
1분이 되었을때 동시 요청 스레드의 수가 300에 도달했고, 남은 2분 동안 300개의 스레드가 동시 요청을 보냈다.
Transactions per Second
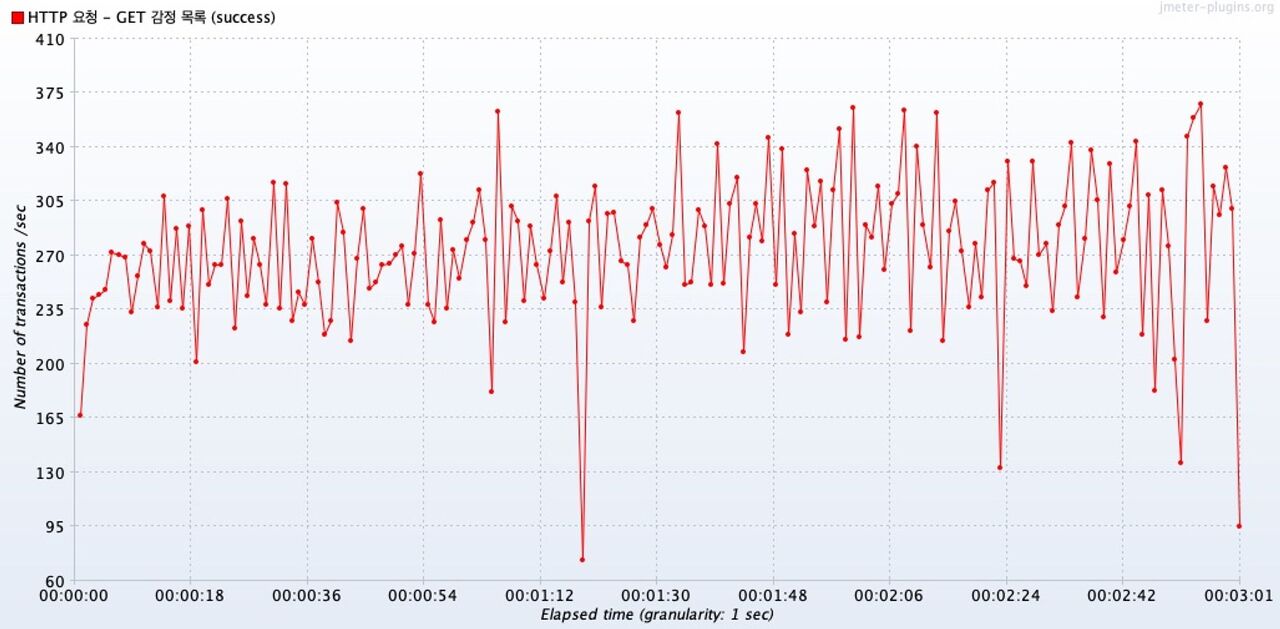
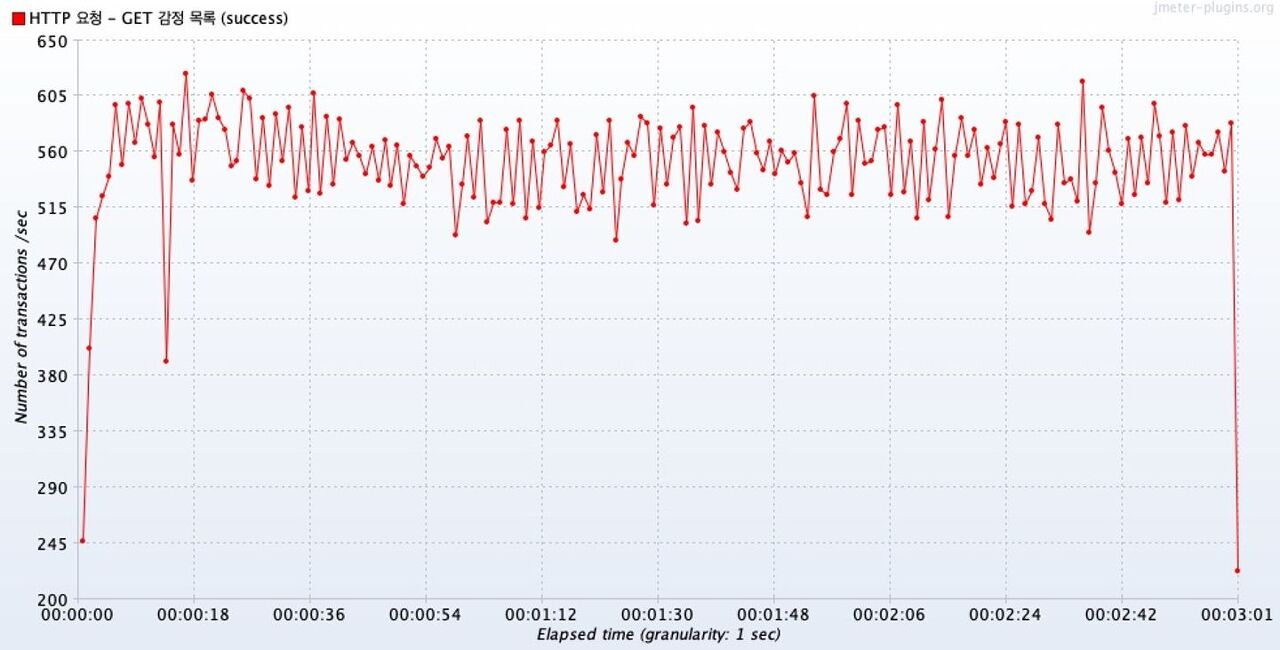
첫번째 그래프는 이번 테스트에서 확인하고자 하는, 캐시가 적용되지 않았을 때의 시간에 따른 트랜잭션 변화 그래프다.
두번째 그래프는 비교를 위한, 이전 테스트의 결과였던, 캐시를 적용했을때의 그래프다.
캐시를 적용하지 않았을 때의 그래프를 보면, 시간이 지남에 따라 처리량이 늘어나는 형태를 보여준다.
하지만 중요한 점은 처리량의 범위가 현저히 차이가 난다.
캐시가 적용되지 않은 테스트는 처리량이 아무리 높아도, 370tps를 넘지 못한다.
하지만 캐시가 적용된 테스트는 대부분 500tps ~ 600tps 범위를 유지했다.
→ 캐시를 적용해 처리량을 높였다.
(Average) Response Times Over Time
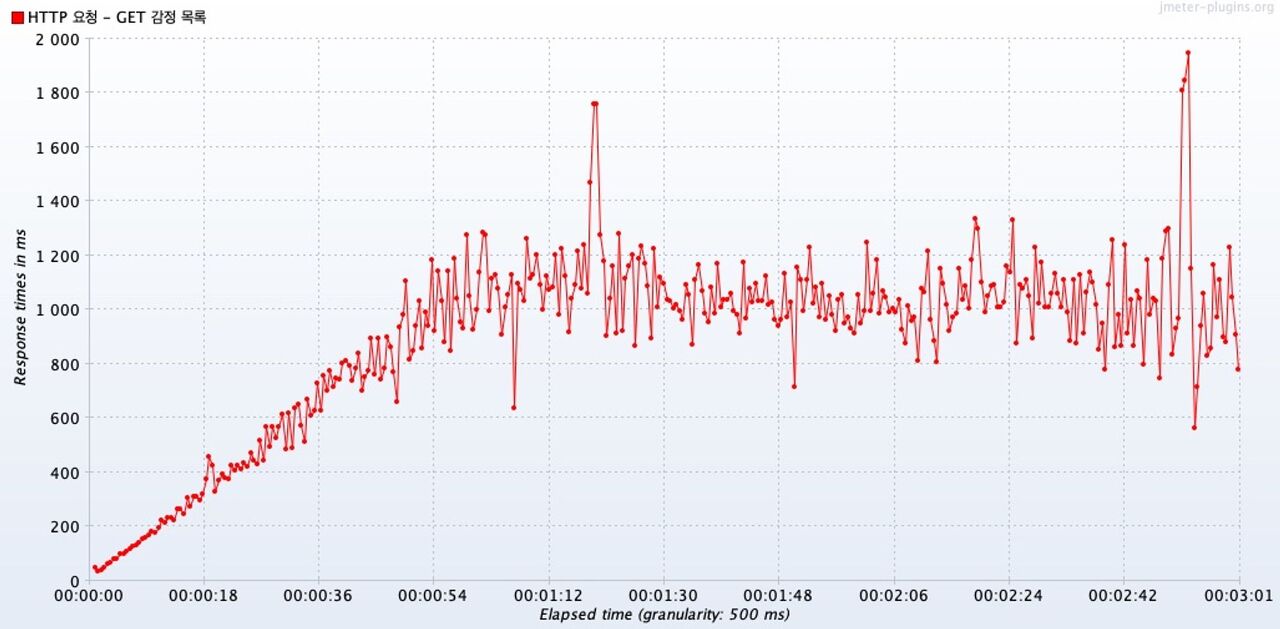
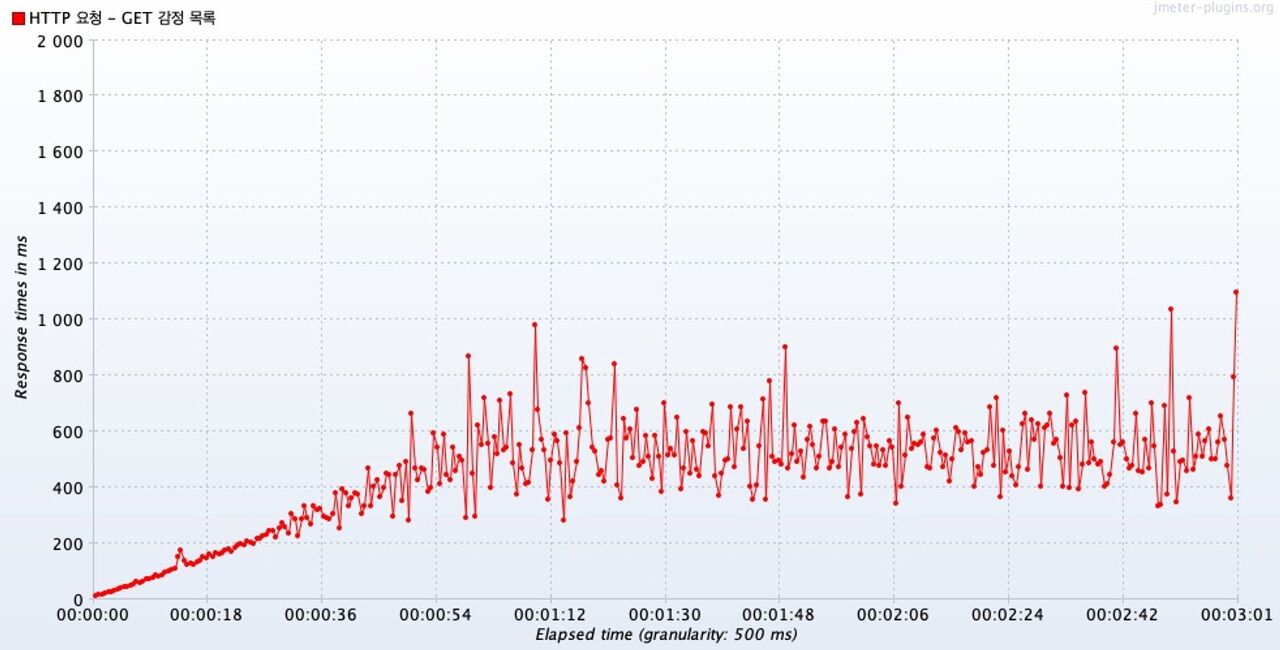
평균 응답시간을 보면, 49초가 경과한 뒤에 벌써 평균 응답시간이 1초를 초과했다.
캐시를 적용했을 때에는 평균 응답시간이 계속 1초를 넘기지 않았다.
→ 캐시를 적용함으로써 동시 요청 상황에서도 응답 시간을 줄였다
Response Times vs Threads
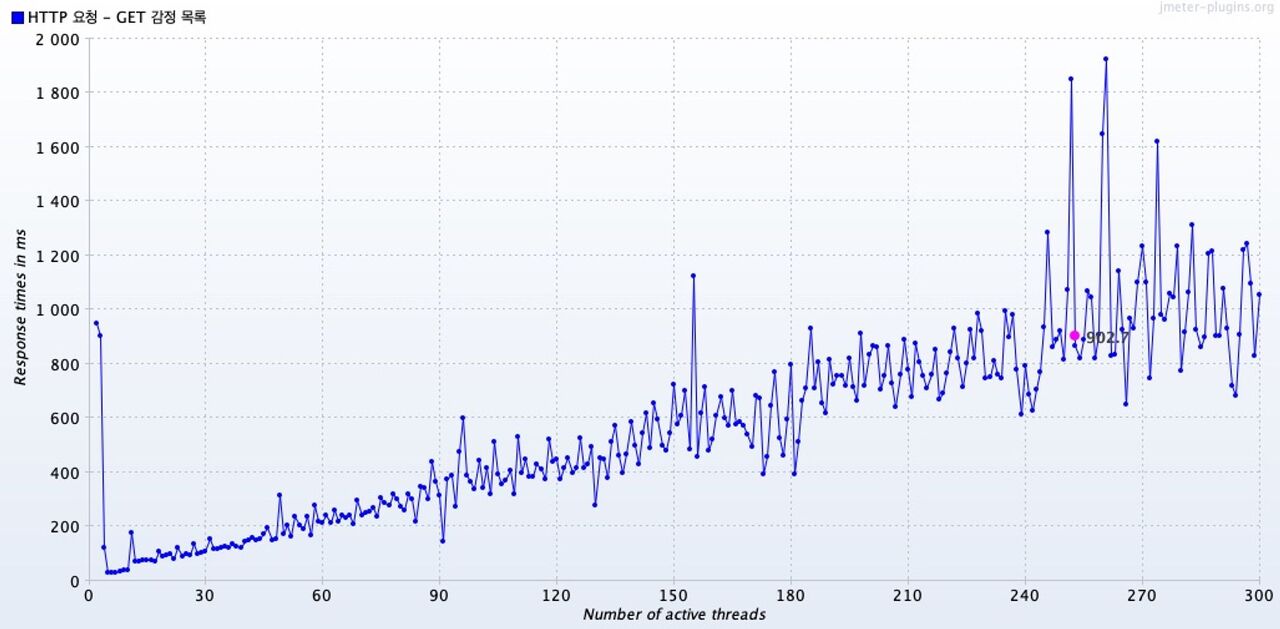
그래프의 핑크색 지점은 총 평균 응답시간을 나타낸다.
캐시를 적용하지 않았을 때의 평균 응답 시간은 902ms로, 캐시를 적용했을 때의 평균 응답시간인 447.7ms에 비해 약 2.01배 길다.
캐시를 적용하지 않은 경우는 전반적으로 평균 응답시간의 범위가 컸다. 동시 요청 스레드가 60개일때부터 이미 200ms를 돌파했다.
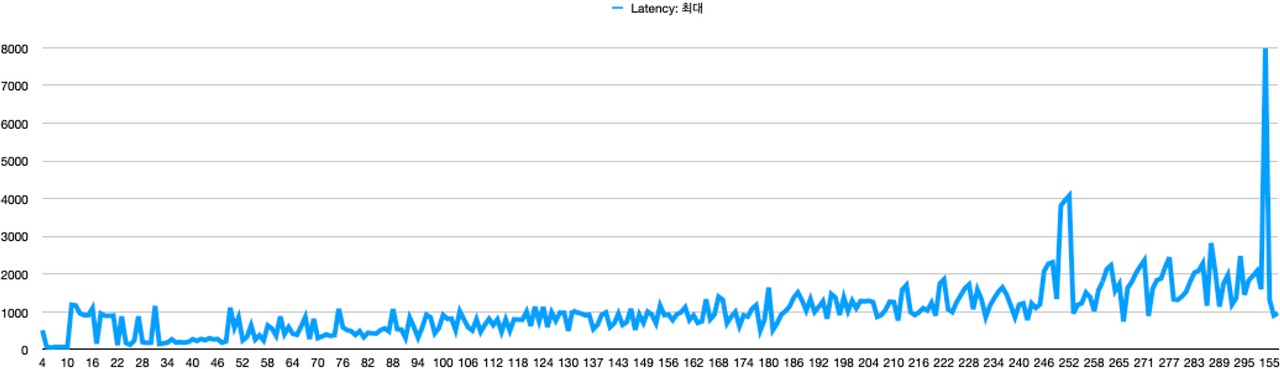
위 그래프를 통해 동시 요청 스레드 수별 최대 응답 시간을 확인해보면, 11개의 동시 요청부터 최대 1초를 초과했다.
물론, 11개 이상의 동시 요청 모두가 최대 응답 시간이 1초를 초과한 것은 아니다.
246개의 동시 요청부터 최대 2초를 초과했다.
캐시를 적용했을 때의 동시 요청 스레드 수별 최대 응답 시간와 비교했을 때,
캐시를 적용했을 떄에는 168개의 동시 요청 이전에는 모든 요청이 아무리 늦게와도 1초를 초과하지 않았지만,
캐시를 적용하지 않았을 때에는 11개의 동시요청까지만 최대 1초 미만으로 유지했다.
물론 테스트를 실행할때마다 약간의 오차는 있지만, 동시 요청 스레드 수가 비교적 적어도 응답 시간이 높아짐을 알 수 있다.
Transaction Throughput vs Threads
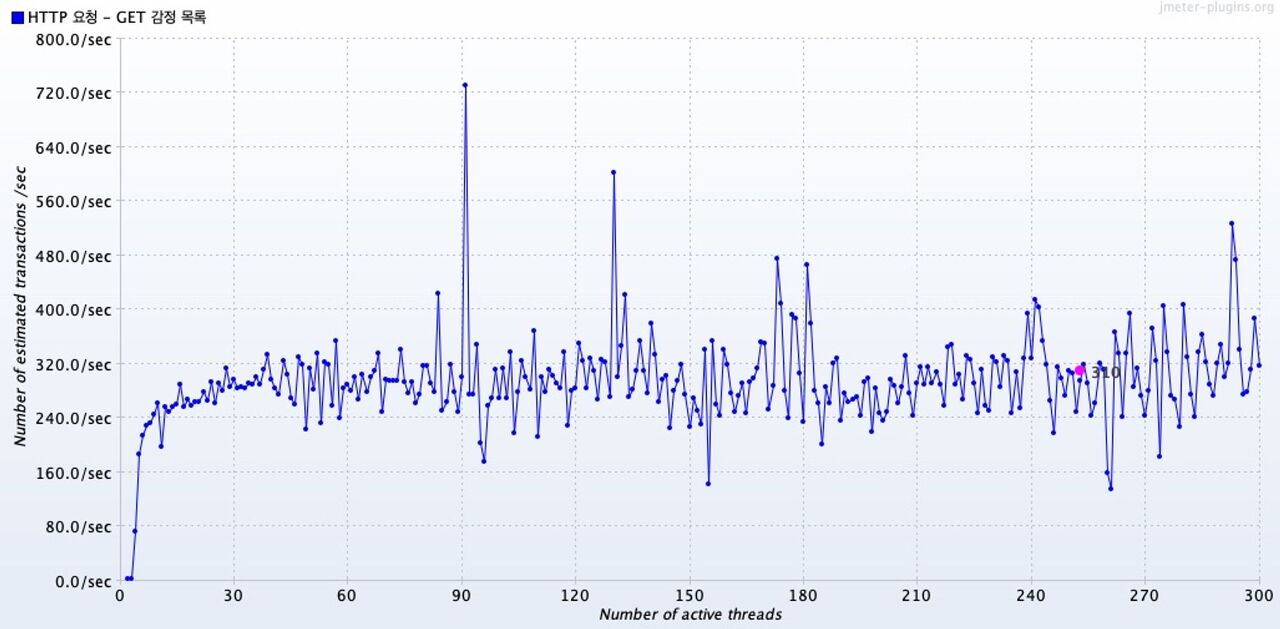
그래프의 핑크색 지점은 총 평균 처리량을 나타낸다.
전반적으로 처리량의 범위가 매우 크고, 처리량 자체가 캐시를 사용했을 때 나타났던 (600~800 tps 구간) 구간에 비해 매우 적다.
( 더 많이 동시 요청을 해봐야 할것 같지만, ) 이번에도 특별한 saturation point가 발견되지 않았다.
총합 보고서

모든 데이터를 총합해서 보면, 평균적으로 902ms가 소요되었고, 최소 19ms 최대 7987 ms가 소요되었다. 오류는 없었다.
평균 처리량이 276.95 tps 로 나타났는데, 이는 캐시를 적용했을 때보다 2배 낮은 수치다.
이렇게 100개의 동시 요청을 1분간 테스트해서, 캐시를 적용했을 때 2배 응답시간이 빠르고 2배 처리량이 늘어난 것을 확인했다.
또, 시행 착오를 통해 이런 테스트 결과를 얻을 수 있었다.
다음 글에서는 일기 생성 API를 성능테스트한 결과를 공유해보고자 한다.
'팀 프로젝트 > 오늘하루를그려줘 : 2023.04 ~' 카테고리의 다른 글
| 응답 속도가 늦는 외부 API 호출 이슈 해결하기 (0) | 2023.08.04 |
|---|---|
| Logback을 통해 로깅 적용하기 (0) | 2023.08.01 |