ConcurrentHashMap의 등장 배경
Map 인터페이스의 구현체로는 HashMap, HashTable, ConcurrentHashMap 등이 있다.
Map 인터페이스를 구현하면, <Key, Value> 형태를 띈다.
이 중, ConcurrentHashMap은 Java 1.5 버전에서 HashTable의 대안으로 처음 소개된 Collection이다.
이전까지는, 멀티 스레드 환경에서 Thread-safe하게 Map을 사용하려면,
- 해당하는 메소드 혹은 해당하는 코드 블럭을 Lock으로 감싸거나
- HashTable을 사용하거나
- SynchronizedMap을 사용하거나
해야했다.
하지만 위 방법에는 문제가 있다.
HashTable, SynchronizedMap을 동기화 시키기 위해 락을 걸면, 특정 엔트리에만 락을 거는 것이 아니라 전체 엔트리에 락을 걸게된다. Thread-safe하지만, 하나의 스레드가 락을 유지하는 동안 다른 모든 스레드는 이 Collection을 사용할 수 없으므로, 오버헤드가 발생하는 것이다.
ConcurrentHashMap은 조작하는 특정 엔트리에 대해서만 락을 걸기 때문에, 데이터를 다루는 속도도 빠르고, 다른 스레드에 불필요한 제한도 주지 않으므로 멀티스레드 환경에서 성능이 더 좋다.
HashMap vs HashTable
HashMap
- key, value에 null을 허용한다.
- 동기화를 보장하지 않는다. ⇒ Thread-safe 하지 않다.
동기화 처리를 하지 않으므로, 싱글 스레드 환경에 적합하고, 데이터를 탐색하는 속도가 빠르다.
HashTable
- key, value에 null을 허용하지 않는다.
- 동기화를 보장한다. ⇒ Thread-safe하다.
동기화 처리를 하므로, 멀티 스레드 환경에서도 사용할 수 있다.
모든 데이터 입출력에 대해 get, put 등의 메소드로 Synchronized를 지원하고 있어, HashMap보다 느리다.
Synchronized가 적용되면 다른 스레드에서 접근할 수 없도록 Lock을 걸고 푸는 작업이 들어가게되고, 이 작업에 많은 시간을 필요로 하기 때문에, Synchronized가 적용되면 속도가 느려진다.
Synchronized Map
어떤 Map 인터페이스(동기화를 지원하지 않는 Map이더라도)를 사용하더라도,
SynchronizedMap으로 랩핑(Wrapping)하여 주면 해당 Map객체는 동기화 맵(Synchronized Map)이 된다.
this.infos = Collections.synchronizedMap(new HashMap<Long, String>());위와 같이 HashMap을 SynchronizedMap으로 랩핑하여 동기화를 보장할 수 있다.
Synchronized Map은 HashTable보다 좋은 성능을 가질 수도 있다.
Synchronized Map과 HashTable이 각각 원소를 조회하고, 추가하는 메소드 get, put 메소드를 확인하면, 동기화를 적용하는 범위가 다르다.
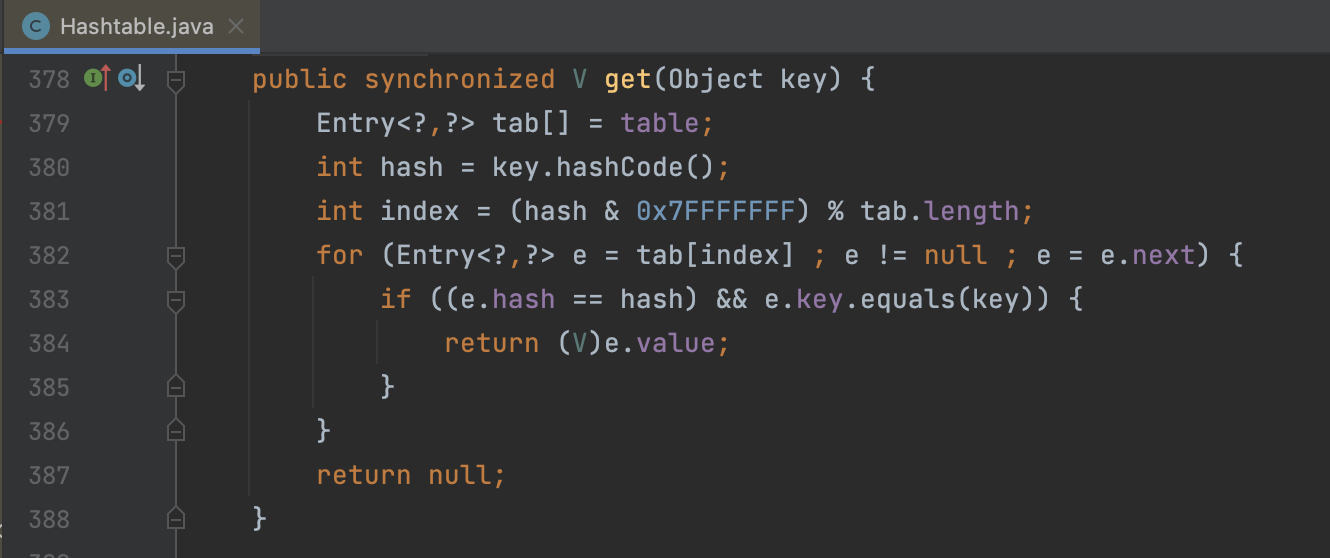
// HashTable의 get
public synchronized V get(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return null;
}
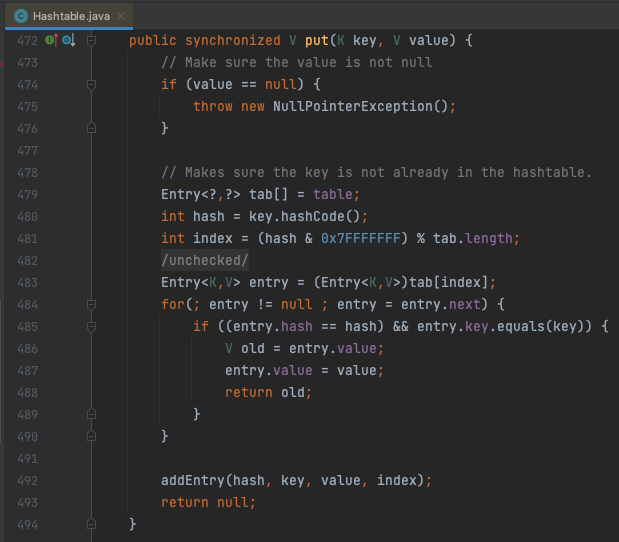
// HashTable의 put
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}HashTable은 메소드 단위로 synchronized를 적용했다.
// Synchronized Map의 get
public V get(Object key) {
synchronized (mutex) {return m.get(key);}
}
// Synchronized Map의 put
public V put(K key, V value) {
synchronized (mutex) {return m.put(key, value);}
}Synchronized Map은 특정 객체 mutex에 synchronized를 적용했다.
따라서, Synchronized Map은 동기화가 필요한 객체에만 동기화를 적용할 수 있고, 필요한 범위에만 동기화를 적용하기 때문에 좋은 성능을 가질 수 있다.
하지만 왜 가질 “수”도 있냐하면, mutex 객체가 Synchronized Map 객체를 가르키는 경우이다.
SynchronizedMap(Map<K,V> m) {
this.m = Objects.requireNonNull(m);
mutex = this;
}
SynchronizedMap(Map<K,V> m, Object mutex) {
this.m = m;
this.mutex = mutex;
}Synchronized Map은 위와 같은 생성자를 가지고 있는데, (위에서 소개한 방법으로) 아래와 같이 첫번째 생성자를 통해 Synchronized Map을 생성할 경우, mutex 객체는 Synchronized Map을 가르킨다.
this.infos = Collections.synchronizedMap(new HashMap<Long, String>());그렇다면, Synchronized Map의 동기화가 적용되는 mutex 객체가 Synchronized Map 객체라면, 이 메소드가 실행 중일 때에 다른 스레드가 Synchronized Map에 접근하지 못하는 것은 동일하다.
결국 객체 전체에 락이 걸리는 것은 동일하므로, Synchronized Map나 HashTable이나 Concurrent Hash Map에 비하면 성능이 떨어진다.
Concurrent Hash Map
Concurrent Hash Map은 Thread-safe하면서, HashMap과 HashTable의 일부 기능들을 제공한다.
특징
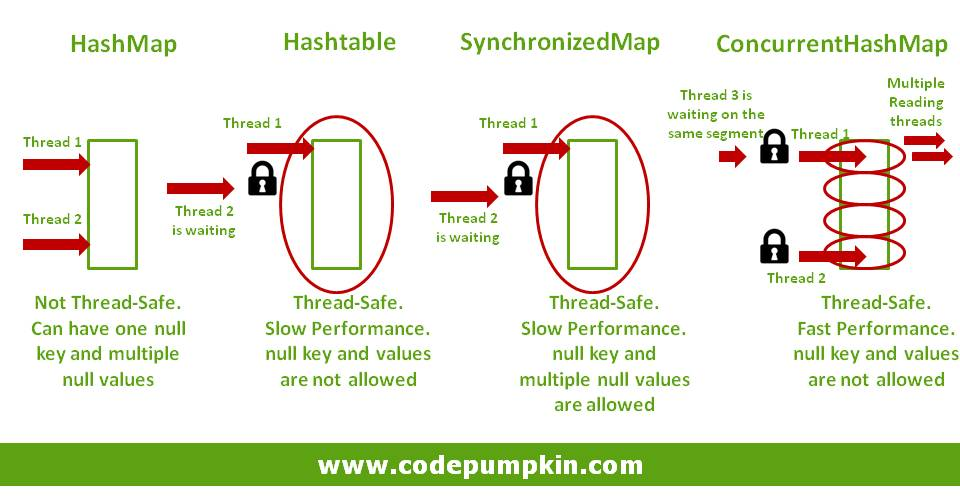
- Thread-safe
- 빠른 성능
- key, value에 null을 허용하지 않음
Concurrent Hash Map이 빠른 이유 : 일부 조건에서 변경할 때만 동기화를 적용한다.
Concurrent Hash Map은 필요한 조건에만 동기화를 적용한다.
SynchronizedMap, HashTable은 대부분의 메소드에서, 즉 조회할 때도 새로운 데이터를 추가할 때도 synchronized가 적용된다.
하지만, Concurrent Hash Map은 일부 조건에서, 변경(삽입 포함)이 이루어질 때에만 synchronized를 적용한다. 그렇기에, 조회할 때에도 synchronized는 적용되지 않아 비교적 빠르게 조회가 가능하다.
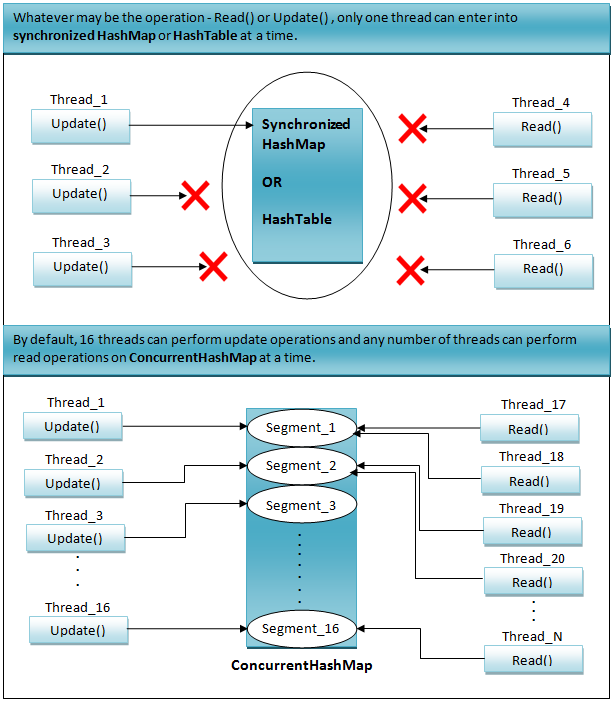
변경시에 synchronized가 적용되지만, 이 또한 특정 조건에서만, 특정 Node에만 동기화가 적용된다.
Concurrent Hash Map가 새로운 데이터를 추가하는 put 메소드를 살펴보면, 일부 조건에서만 특정 Node에 대해 synchronized가 적용됨을 볼 수 있다.
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh; K fk; V fv;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else if (onlyIfAbsent // check first node without acquiring lock
&& fh == hash
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
return fv;
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}Concurrent Hash Map은 데이터를 읽을 때 synchronized를 사용하지 않는다.
Concurrent Hash Map이 동기화를 사용하는 곳은 변경이 일어나는 일부의 경우 뿐이다.
아래는 Concurrent Hash Map에서 Key를 통해 Value를 찾는 get 메소드의 코드로, synchronized는 사용되지 않았다.
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}따라서, Concurrent Hash Map은 조회할 때에는 synchronized를 사용하지 않으므로, Synchronized Hash Map이나 HashTable보다 빨리 조회한다.
Concurrent Hash Map은 volatile을 사용한다.
Concurrent Hash Map은 volatile을 사용하여 synchronized 없이도 Thread-safe하게 동작한다.
예를 들어, 위에서 소개한 putVal 메소드는 volatile을 사용한다.
putVal 메소드는 아래와 같은 구조로 동작한다.
- 반복문을 실행한다.
- 새로운 노드를 삽입하기 위해 bucket값을 가져와 비어있는지(null값) 확인한다.
- 비어있다면 Node를 담고있는 volatile 변수에 접근하여 기댓갑(null)과 일치하는지 확인한다.
- 일치한다면 Node를 삽입한다.(lock은 걸지 않는다.)
- 일치하지 않는다면 다시 1번으로 간다. (재시도)
- 비어있지 않다면 synchronized를 사용하여 lock을 건다.
즉, Concurrent Hash Map은 비어있는 버킷에 Node를 추가할 때, volatile 사용하여 Thread safe하게 접근한다.
Concurrent Hash Map은 Node를 저장하는 필드 table에 volatile 키워드가 적용되어 있다.
volatile을 사용하면 공유 자원에 대해 읽고, 변경할 때 메인 메모리로부터 읽고 메인 메모리에 변경한다.
각 스레드의 cpu의 캐시로 옮겨와 읽거나, 각 cpu의 캐시로 옮겨와서 연산하여 변경하는 값도 각 cpu의 캐시에서 수행하지 않는다.
따라서, 멀티 스레드 환경에서 예상하지 못한 값을 조회하는 것을 방지할 수 있다. 멀티 스레드 환경에서, 각 스레드가 변수 값을 읽어올 때, CPU 캐시의 값에 저장된 값은 서로 다를 수 있으므로, 메인 메모리에서 읽어옴으로써, 변수 값 불일치 문제를 방지할 수 있는 것이다.
Concurrent Hash Map은 각 Node를 저장하는 table 변수가 volatile이 적용되어있음을 이용해서, 확실히 이 버킷이 null인지 원자성을 보장할 수 있도록 확인한 후에, 새로운 노드를 추가한다.
따라서, Concurrent Hash Map은 비어있는 버킷에는 volatile 키워드의 특성을 활용하여 확실히 비어있는지 확인한 후에 Node를 추가함으로써, Thread-safe하게 Node를 추가한다. 그리고, synchronized를 사용하지 않았고 락을 걸지 않기 때문에 더 좋은 성능을 낸다.
Concurrent Hash Map은 데이터를 변경하는 일부의 경우에 synchronized를 사용한다.
Concurrent Hash Map도 HashTable, Synchronized Hash Map 처럼 synchronized를 사용하긴 하지만, 데이터를 변경하는 일부의 경우에, 즉 필요할 때에만 락을 건다.
예를 들어, 위에서 소개한 putVal 메소드는 volatile도 사용하지만, synchronized도 사용한다.
이미 Node가 있는 버킷에 Node를 추가할 때, putVal 메소드에서는 synchronized 사용하여 Thread safe하게 동기화하여 처리한다.
즉, Concurrent Hash Map은 이미 Node가 있는 버킷에 Node를 추가할 때에는, 추가할 버킷에만 synchronized를 적용해 락을 건다.
이 경우, 여러 스레드에서 쓰기 연산을 할 수 있기 때문에 volatile이 아닌 synchronized를 사용했다.
여러 스레드에서 읽기가 아닌 쓰기를 할 때에 volatile을 이용하면, 메인 메모리에 썼음에도 불구하고 어느 스레드의 값은 반영되지 않는다. 따라서, 해당 버킷에 락을 걸어 다른 스레드는 쓰기 연산을 못하도록 제한하였다.
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
...
}
따라서, Concurrent Hash Map은 필요할 때에만 synchronized를 적용해 더 효율적으로 데이터를 관리한다.
당연히, Concurrent Hash Map에는 putVal 뿐만 아니라, 다른 메소드에도 synchronized를 사용하는 곳이 있다. 하지만, HashTable, Synchronized Hash Map과 달리 필요할 때에만 사용한다.
레퍼런스
https://codepumpkin.com/hashtable-vs-synchronizedmap-vs-concurrenthashmap/
https://javaconceptoftheday.com/synchronized-hashmap-vs-hashtable-vs-concurrenthashmap-in-java/
https://nesoy.github.io/articles/2018-06/Java-volatile
https://ttl-blog.tistory.com/238
https://yeoonjae.tistory.com/entry/Java-ConcurrentHashMap에-대해-알아보자작성중
https://codingdog.tistory.com/entry/java-synchronizedmap-데이터가-포장된-잠금-객체
'Java & Spring' 카테고리의 다른 글
| 변수 동기화 하기 - atomic, volatile, synchronized (0) | 2023.07.04 |
|---|---|
| Consistent Hashing (0) | 2023.06.16 |
| Interceptor (0) | 2023.05.23 |
| Filter (0) | 2023.05.16 |
| 이펙티브 자바 - 아이템 21: 인터페이스는 구현하는 쪽을 생각해 설계하라 (0) | 2023.05.08 |